什么是AnimateDiff?
AnimateDiff是一个创新的框架,由上海人工智能实验室、香港中文大学和斯坦福大学的科研团队共同开发。该框架将个性化文本到图像模型扩展为一个动画生成器,其主要特点是能够应用从大规模视频数据集中学习到的运动模式,以增强静态图像的动态表现力。AnimateDiff旨在通过文本描述来控制动画的内容和风格,省去了对模型进行额外调整的需要。
如何访问AnimateDiff
若想深入了解AnimateDiff,可以访问以下链接获取更多信息:
– 官方项目主页
– Arxiv研究论文
– GitHub代码库
– Hugging Face Demo
– OpenXLab Demo
AnimateDiff的核心功能
AnimateDiff具备以下独特的功能特性:
– 个性化动画创造:用户可以通过简单的文本描述,将个性化的图像模型转化为动态的动画序列,确保动画与输入的文字紧密相关。
– 简化模型调整:AnimateDiff的优势在于它允许用户无需对模型进行特定的调整即可生成动画,直接使用预训练的运动建模模块。
– 风格一致性维持:在动画生成过程中,AnimateDiff保持了原有模型的风格特性,确保动画内容与特定风格和主题的一致性。
– 跨领域兼容性:框架支持不同类型的个性化模型,涵盖动漫、2D卡通、3D动画以及现实摄影等多个领域。
– 易于集成:AnimateDiff的设计理念使得它容易与现有的个性化T2I模型集成,使得用户即使没有深厚的技术背景也能轻松使用。
探索AnimateDiff的工作机制
AnimateDiff的工作原理可以通过以下几个步骤来理解:
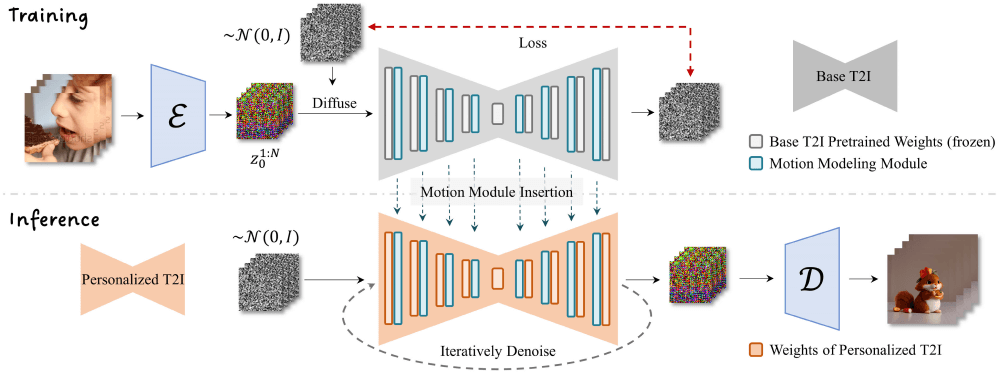
1. 运动建模模块整合:在现有文本到图像模型的基础之上,加入一个特别设计的运动建模模块,以理解和生成动画所需的运动信息。
2. 运动模式学习:通过在大规模视频数据集上的训练,运动建模模块学习并掌握运动模式,这一过程不会改变基础T2I模型的参数。
3. 注意力机制应用:AnimateDiff采用了标准的注意力机制来管理时间维度,允许模型在生成每一帧时都考虑到其前后帧的信息。
4. 动画序列生成:在训练完成后,运动建模模块可以被整合进任何基于相同基础的个性化模型中,生成与文本描述相匹配的动画。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号