什么是ScreenAgent
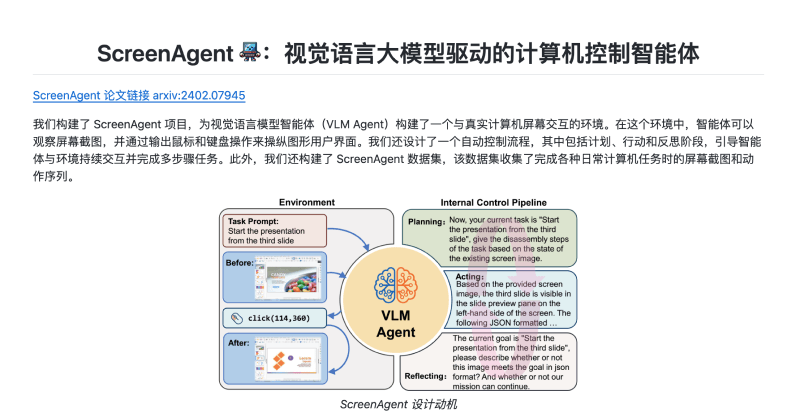
ScreenAgent是一款由吉林大学人工智能学院团队打造的先进计算机控制智能体。它以视觉语言模型(Visual Language Model,简称VLM)为基础,实现了与计算机屏幕的智能化交互。该智能体的开发遵循了“计划-执行-反思”的运作模式,通过观察屏幕内容,生成相应的鼠标和键盘指令,以执行复杂的图形用户界面(Graphical User Interface,简称GUI)任务。
ScreenAgent的官方资源链接
- GitHub 代码库:探索ScreenAgent的源代码,了解其技术实现。
GitHub Repo - Arxiv 研究论文:阅读ScreenAgent的前沿研究论文,深入了解其理论基础。
Arxiv Paper
ScreenAgent的运行模式
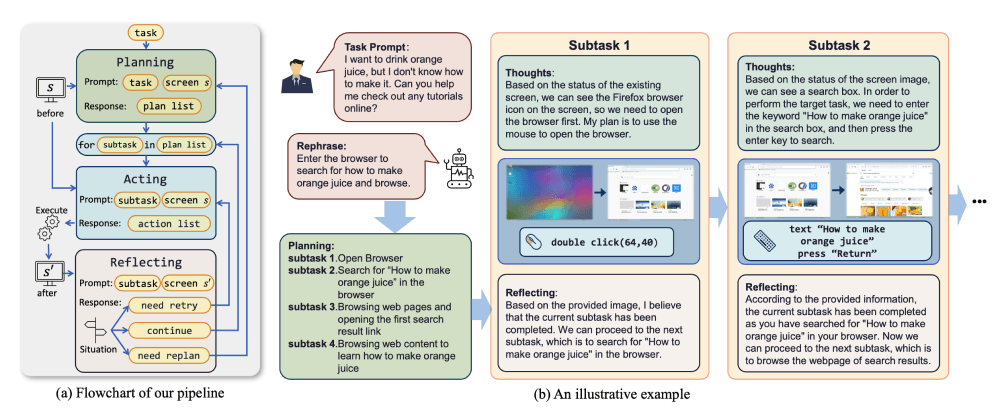
ScreenAgent的运作流程可以通过以下步骤进行概括:
- 屏幕观察:智能体通过VNC协议观察桌面操作系统的实时图像,从而理解屏幕上的内容。
- 动作生成:基于屏幕上的观察结果,智能体生成并输出一系列动作指令,如鼠标移动、点击、滚动等。
- 任务规划:面对用户的复杂任务,智能体会分解为多个子任务,并规划出完成这些子任务的指令序列。
- 执行动作:按照规划阶段的指令,智能体执行相应的动作指令。
- 反思评估:执行完毕后,智能体会进行结果评估,决定是否需要调整策略或继续后续动作。
ScreenAgent的核心技术
ScreenAgent的核心技术要点包括:
- 视觉语言模型(VLM):
- 结合视觉和语言处理的技术,使智能体能够理解屏幕截图和用户指令,规划并执行动作任务。
- 强化学习环境:
- 智能体在与之交互的环境中观察状态、执行动作,并根据结果获得奖励,以此来优化自己的策略。
- 控制流程:
- 包括规划、执行和反思三个环节,确保智能体能够高效完成复杂任务。
- 数据集和评估:
- 使用特定的数据集进行训练和评估,如CC-Score为衡量计算机控制任务表现的指标。
- 模型训练:
- 利用监督学习、强化学习及人类反馈循环等技术,来训练ScreenAgent模型,使其更精准地执行任务。
通过这些技术的结合,ScreenAgent能够智能地与真实世界中的计算机系统进行交互,极大地提高了自动化处理复杂GUI任务的潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号