在大模型领域的激烈竞争中,DeepSeek-R1的问世意义非凡,其以突出的性价比优势,拉开了大模型性价比竞争的帷幕。Meta、OpenAI等国外头部大模型厂商,面对这一局势,纷纷采取复刻或变相降价策略。例如,OpenAI晚两周发布的o3-mini模型,定价较前代o1-mini降低超6成,比完整版o1模型便宜超9成。国内大模型厂商也迅速做出反应,百度宣布文心一言于4月1日全面免费开放,此前其采用基础版免费、专业版收费模式。
这场看似单纯的价格竞争,背后实则是技术实力与用户市场的深度较量。在此过程中,中国算力市场正经历深刻变革。《2025年中国人工智能计算力发展评估报告》将中国算力发展的四大变化呈现在大众眼前。
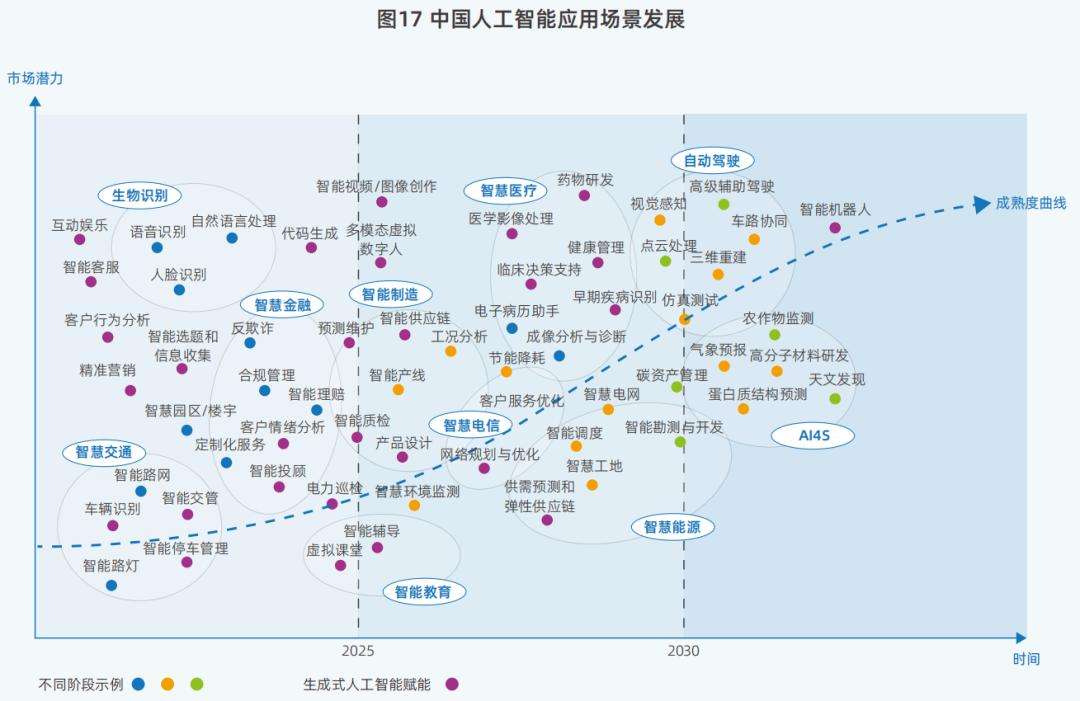
首先是算力效率之变。DeepSeek通过算法优化,大幅降低大模型训练、推理对高端GPU的依赖,提升模算效率,这也是其实现高性价比的关键。DeepSeek-R1训练成本仅557万美元,不足OpenAI同类产品的5%,却能在部分任务中超越GPT-4模型。其“四两拨千斤”的研发模式,注重算法创新、架构优化和资源高效利用,或带动业界对模算效率的追求。同时,DeepSeek采用的MoE(混合专家模型)架构实现了更高成本效益,相比Dense架构优势明显,未来或引发业界对该架构的模仿借鉴。当下,众多企业接入DeepSeek模型,多形态、多参数的模型协同发展,促进了AI技术的扩散。
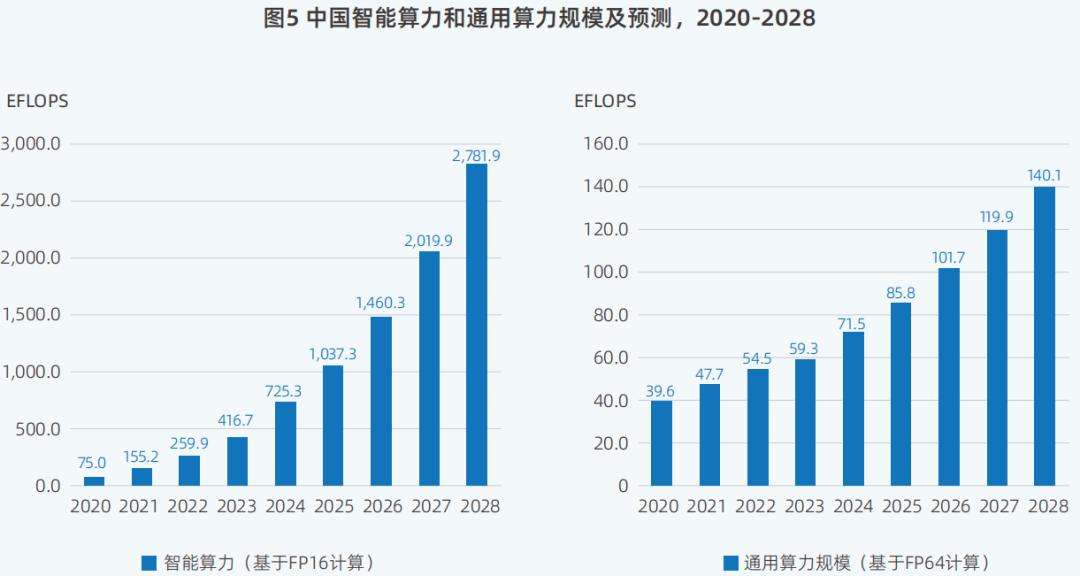
算力结构也发生了显著变化。国内智能算力规模极速扩张,2024年中国智能算力规模达725.3EFLOPS,同比增长74.1%,是近5年来的总量最高峰,增幅远超通用算力。AI相关市场规模快速膨胀,尽管业界对大模型的Scalinglaw(规模法则)存在争议,但它仍是推动AI算力需求增长的主因。DeepSeek算法效率提升,带动更多用户和场景,推动大模型普及与应用落地。然而,单纯堆叠训练算力并非长久之计,多模态模型应用等热潮涌现,激发了AI推理需求。《报告》预测,后续推理算力规模将超训练算力规模,推理服务器占比也将大幅提高,这在浪潮信息的业务中已得到印证。
算力供应方式也日益多元化。供给端形成了数据中心服务商、云服务商、硬件厂商和相关AI创企多点提供AI算力资源的格局。需求端方面,生成式AI推动企业使用智算服务,中国智算服务市场规模预计将持续增长。同时,用于推理的一体机受到市场追捧,“开源+一体机”或成企业AI服务爆款模式,市面上已有60家DeepSeek一体机企业。浪潮信息推出的元脑R1推理服务器,可单机部署运行DeepSeek-R1满血版671B模型,咨询购买的客户数正直线上升。
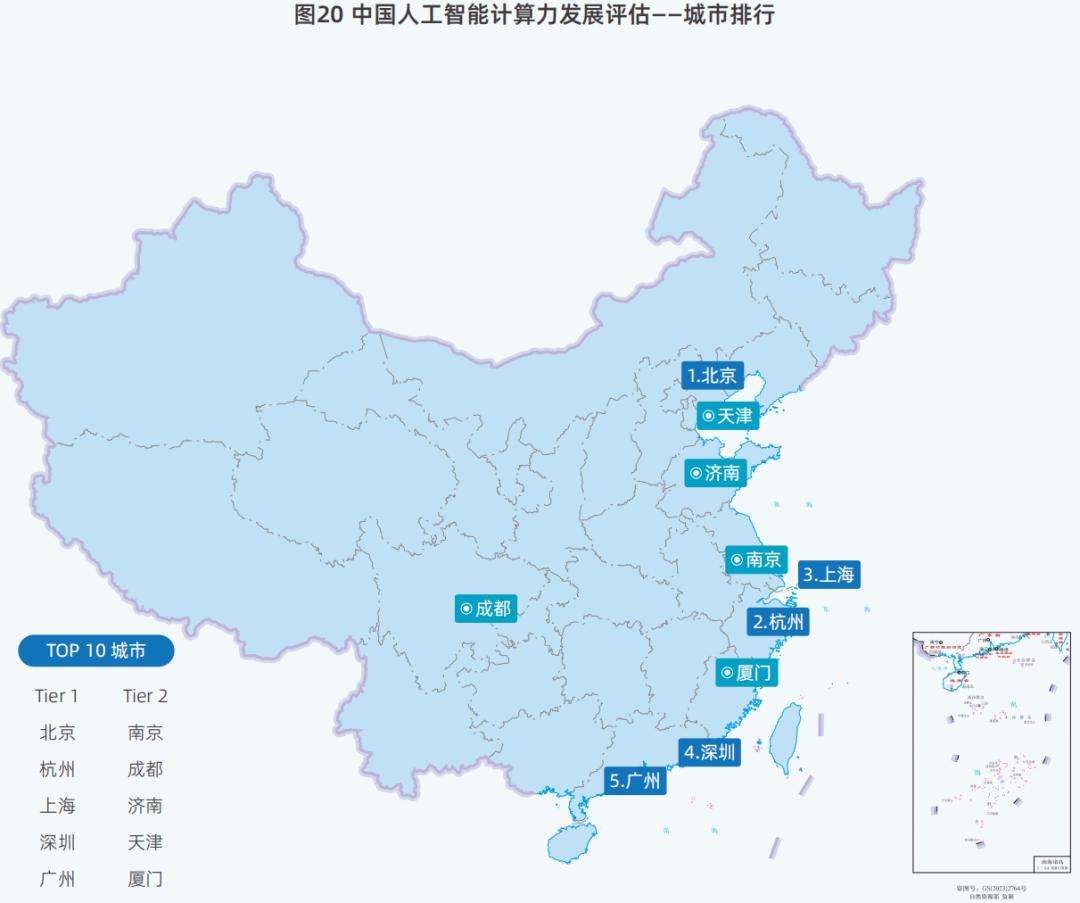
城市AI排名同样有了新变化。北京、杭州、上海在国内城市AI算力排行榜中位居前三,北京凭借人才、企业和政策优势居首,杭州提出相关发展目标并颁布政策,上海加速推动产业集群建设。此外,广州、成都等城市的AI算力排名也有所提升。在不同行业的AI应用渗透度方面,互联网行业排名第一,AI原生应用覆盖多个场景,金融和制造行业的排名也有所上升。
综上所述,国内算力产业发展蓬勃,但也面临挑战。《报告》提出算力“扩容”和“提效”并行策略,“扩容”旨在加强算力供给能力,“提效”则聚焦于提高算力利用率。未来,大模型产业的发展将为国内算力市场注入新活力。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号