Saba语言模型亮相,聚焦特定区域语言文化 近日,MistralAI推出新型语言模型Saba,该模型将重点放在提升对中东和东南亚地区语言及文化差异的理解上。
参数规模与性能优势 Saba模型参数为240亿,虽小于不少竞争对手,但MistralAI称其在保证准确性的同时,速度更快且成本更低。它的架构或与MistralSmall3模型类似,能在性能较低的系统上高效运作,单GPU设置下每秒可处理超150个令牌。
语言处理专长 Saba在处理阿拉伯语和印度语方面表现出色,尤其是泰米尔语和马拉雅拉姆语等南印度语。MistralAI的基准测试表明,Saba在阿拉伯语方面成绩优异,同时英语能力也相当不错。
实际应用场景目前,Saba已被运用到现实场景中,如阿拉伯语虚拟助手以及能源、金融市场和医疗保健领域的专用工具。其对当地习语和文化的理解,使其能有效生成特定区域的内容。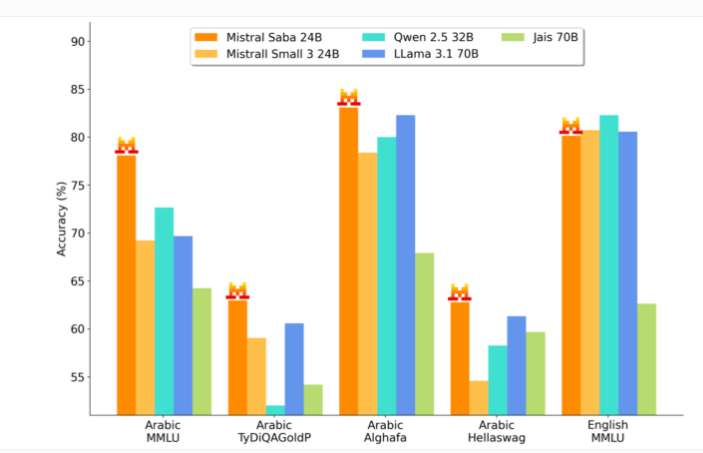
访问方式与开源情况 用户可通过付费APi或本地部署的方式访问Saba。需要注意的是,和Mistral AI的其他模型一样,Saba并非开源模型。
区域语言模型发展趋势 Saba的推出反映了AI领域对特定区域语言模型需求的关注。其他组织如OpenGPT-X项目(发布Teuken-7B模型)、OpenAI (开发日语专用GPT-4模型) 和EuroLingua项目 (专注于欧洲语言)也在开展类似研究。传统大型语言模型多依赖大量英文文本数据集训练,易忽视特定语言细微差别,而Saba致力于填补这一空白,提供更精准、契合当地文化背景的语言处理能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号