去年底OpenAI 12天连发的最后一日,ARC Prize赚足眼球,其发布5年的基准ARC-AGI迎来得分优良的挑战者o3系列模型。两个多月后,AI领域变化巨大,性能强大的开源低成本推理模型DeepSeek-R1,成为国内AI或云服务商标配,并被集成到众多应用与服务中。
ARC Prize发布报告显示,DeepSeek-R1在ARC-AGI-1上表现逊于OpenAI的o1系列模型,更不及o3系列,不过其具备成本低的独特优势。上周六,ARCPrize推出新的1v1对抗性基准SnakeBench,DeepSeek-R1在此超越o1-mini,与o3-mini差距微小。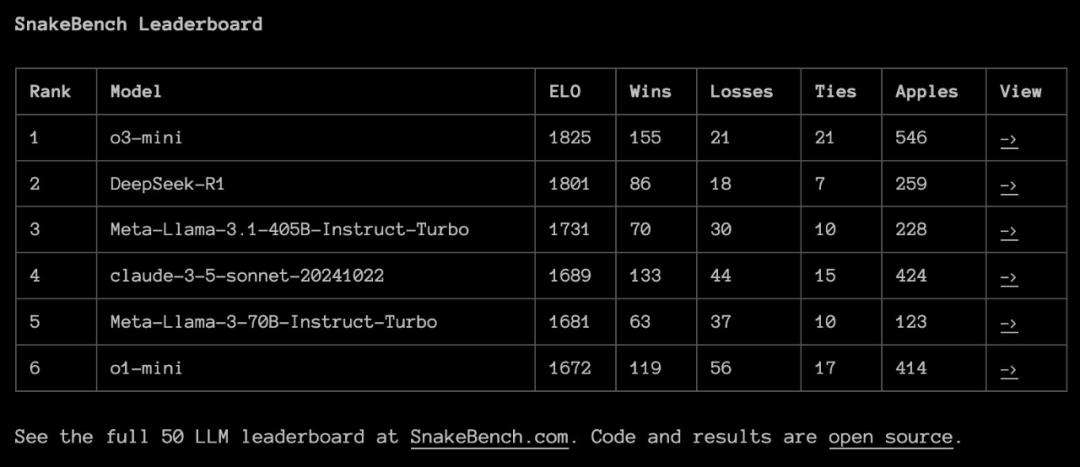
SnakeBench设计灵感源自著名AI研究科学家Andrej Karpathy的推文,涉及让AI智能体在游戏中对抗评估的思路。ARCPrize认为,游戏作为评估环境可检验LLM的实时决策、多重目标、空间推理、动态环境等多种能力。
ARCPrize用50个LLM进行2800场比赛,为模型的“贪吃蛇实时策略和空间推理”能力排名。比赛以文本格式提供棋盘,明确XY坐标系,游戏时随机初始化蛇,两条蛇同时选下一步动作,蛇撞到墙、自己或对方时游戏结束,之后计算Elo评分。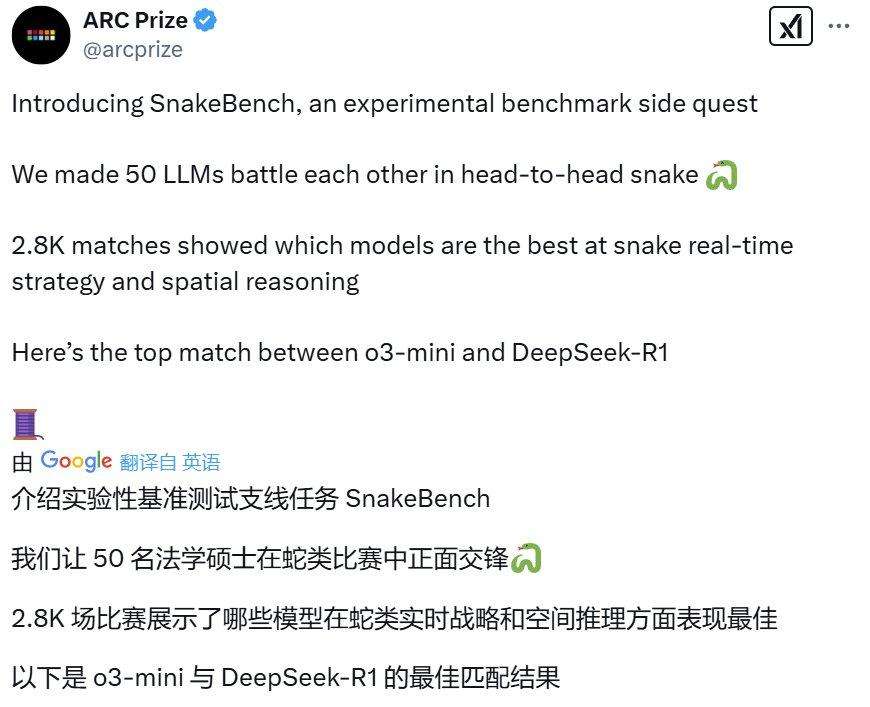
整体来看,Big LLaMA、o1、o3、Sonnet 3.5和DeepSeek表现最佳,其他LLM常撞墙。ARCPrize官网列出多局比赛详情,比如DeepSeek-R1与o3-mini的比赛,能看到LLM每步选择及理由,还有DeepSeek-R1完整思考过程。
ARC Prize总裁GregKamradt总结关键发现:推理模型主导,o3-mini和DeepSeek赢得78%比赛;LLM常误解文本格式棋盘布局,导致定位错误或撞尾;较低档模型表现差,基本空间推理是LLM巨大挑战;上下文关键,需加载大量信息辅助LLM做正确选择。
值得一提的是,LLM对抗竞技易复现,CoreView联合创始人让deepseek-r1:32b与qwen2.5-coder:32b进行贪吃蛇比赛,也有用户分享让有视觉能力的LLM玩贪吃蛇的经历,结果与SnakeBench不同,gemini表现最佳。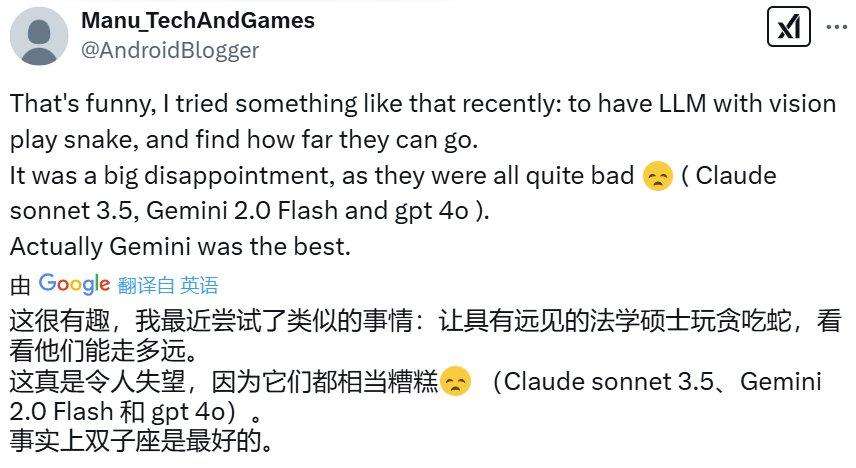



 鄂公网安备42010402001699号
鄂公网安备42010402001699号