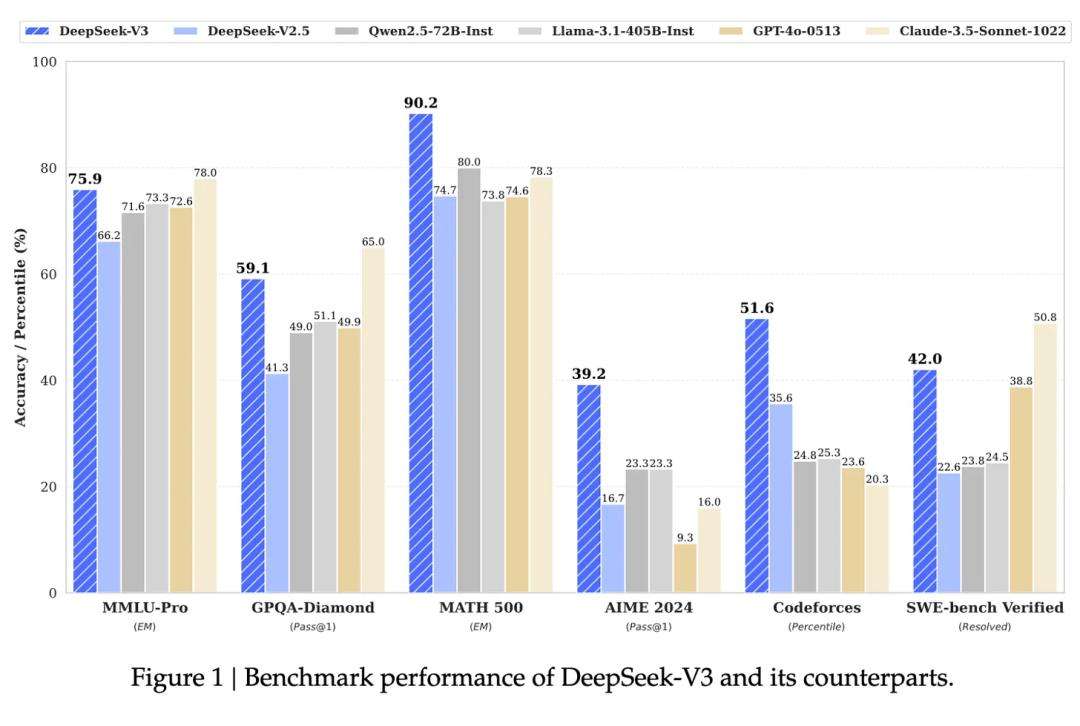
2024年12月26日,杭州的“深度求索”这家中国初创公司,发布的全新一代大模型DeepSeek-V3,震惊了硅谷。美国CNBC电视台评价其为“一种新的模式,让整个山谷都嗡嗡作响”。在多个基准测试里,DeepSeek-V3性能超越其他开源模型,与顶尖闭源大模型GPT-4o不相上下,尤其在数学推理上更是领先。令人瞩目的是,它研发仅花558万美元,训练成本不到GPT-4o的二十分之一。
DeepSeek-V3打破了中国AI公司只会照搬硅谷的成见,它以MLA、DeepSeekMoE等多项开创性技术,提升了模型性能和训练效率。这股“来自东方的神秘力量”,幕后资方是幻方量化。幻方量化在2023年成立“深度求索”开始研发DeepSeek大模型,整个团队仅139人,远少于OpenAI的1200人。
故事要从幻方量化的创始人梁文锋说起。2008年,从浙大软件工程专业毕业的他,没有进入大厂,而是在成都出租屋研究用计算机赚钱的途径,最终决定投身量化投资。2010年沪深300股指期货推出,他和团队借此盈利,自营资金超5亿元。随着深度学习算法突破,2015年梁文锋与校友创立幻方量化,致力于打造世界顶级量化对冲基金。
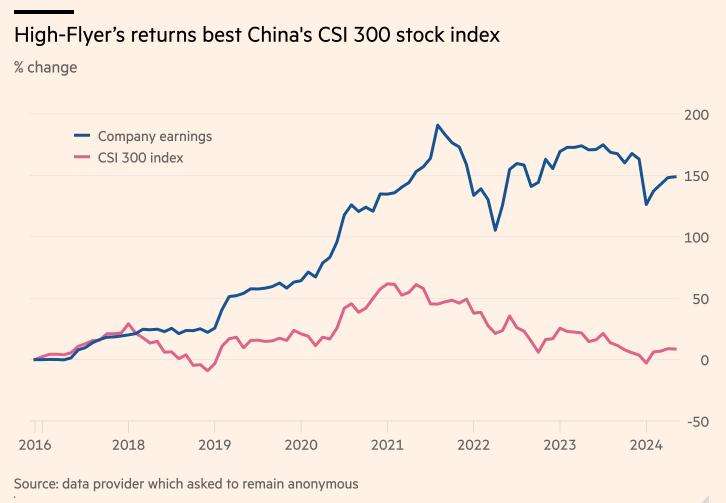
随着AI交易策略对算力需求的增长,从2019年起,幻方量化大规模布局AI算力,建成“萤火一号”“萤火二号”等算力集群。在AI大模型尚未爆发时,这种举动看似疯狂。而当谷歌提出Transformer架构,OpenAI基于此推出chatgpt引爆大模型时代后,梁文锋带领团队却尝试改进Transformer架构。
他们大胆采用MLA、DeepSeekMoE等技术,借助前期储备的算力,成功推出DeepSeek-V3。梁文锋认为“中国也要逐步成为创新贡献者”,DeepSeek以“探索通用人工智能的本质”为使命,在其他厂商忙于商业化时,专注基础研究。
梁文锋选人坚持本土原则,看重热爱和好奇心。在DeepSeek,年轻人不受传统束缚,如MLA架构就源于一位年轻人的灵感。公司内部管理松散,却充分调动了员工的积极性,让DeepSeek-V3得以诞生。梁文锋的理念和行动,让我们看到中国AI突破的希望,“中国AI不可能永远处在跟随的位置”。如今,众多新生代企业家正推动中国科技产业迈向新高度。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号