在自然语言处理领域,大型语言模型(LLMs)的迅猛发展带来巨大变革,广泛应用于代码助手、搜索引擎及个人AI助手等场景。然而,传统“下一个token预测”范式存在局限,处理复杂推理和长期任务时,模型需大量训练才能实现深层次概念理解。

为突破这一困境,Meta等机构研究者推出“连续概念混合”(CoCoMix)这一新颖预训练框架。此框架保留了下一个token预测的长处,借助稀疏自编码器(SAE)学习到的连续概念,革新学习机制,即将最具影响力的概念与token的隐藏表示交错结合。
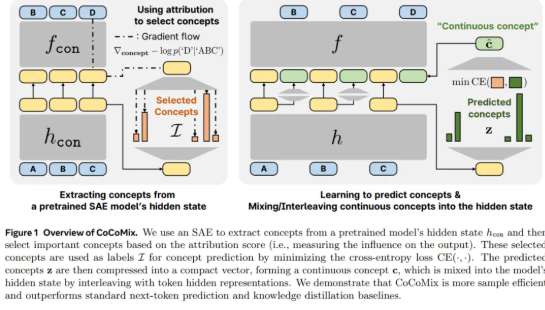
实际应用中,研究者对CoCoMix展开广泛评估,涉及多个语言建模基准和不同规模模型。结果表明,CoCoMix在训练token数量减少21.5%的情况下,仍能达到与传统token预测相近的性能。特别是在从小模型提取概念指导大模型的弱到强监督场景中,表现出显著改进。
值得一提的是,CoCoMix具备突出的可解释性和可操控性。通过观察模型预测表现,能清晰知晓模型重点关注的概念,还可通过调整概念大小操控输出结果,为模型分析和优化提供全新视角。
总体而言,CoCoMix是对现有语言模型训练方式的创新之举,也是Meta引领大模型发展趋势的重要尝试。随着技术发展,这一框架有望成为未来自然语言处理领域的关键助力,推动AI迈向更智能的发展阶段。项目地址:https://github.com/facebookreseARCh/RAM/tree/main/projects/cocomix
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号